Mining Mimecast: brute forcing your way to success
This article was originally published via the Schillings cyber blog, where I previously worked.
Mimecast is one of the largest cloud e-mail security providers in Europe and serves over 26,400 organisations globally — Schillings being one of them [1]. If you’re in the security industry, you’re more than likely familiar with them. Mimecast’s “bread and butter” is defending against phishing, ransomware and other targeted e-mail attacks. In fact, our red teams know first-hand that they’re pretty good at it — it’s always a fun challenge eluding their sandbox technologies.
The most useful Mimecast feature for preventing phishing attacks is “URL Protect”. It essentially acts as a URL shortener — similar to bit.ly — and rewrites all inbound e-mail links. When a link is clicked, Mimecast checks the original URL against various threat intelligence platforms and makes a decision whether it is safe for the user to proceed or not. It works something like this:
-
Alice sends an e-mail to Bob with a link to a file containing confidential financial information.
-
Bob’s Bank uses Mimecast’s e-mail security and so the link is automatically changed to https://protect-eu.mimecast.com/s/xflWBoOFLLcX before being delivered to Bob’s Inbox.
-
Bob clicks the link, which Mimecast considers to be safe, and then is transparently redirected onwards to Alice Accounting’s secure file sharing platform.
Not an ideal way to share confidential information but something we see all too much of.
You’ve probably guessed where I’m going with this… ” I wonder if I could brute force Mimecast’s shortened URLs”. And of course, this is nothing new. There have been previous attacks on the biggest URL shortener services across the web. However, Mimecast URLs are automatically generated upon receipt of an e-mail. The Alices and Bobs of the world don’t even know it’s happening or have a choice in the matter.
Decoding the URLs
By using some Google-fu, and checking phishing threat platforms, I was able to gather a bunch of protected URLs and instantly noticed three patterns:
-
The ID is seemingly Base62 encoding as it only uses the characters 0-9A-Za-z.
-
It is always between 12 and 14 characters.
-
The 5th character is always B.
Taking the mean length of 13, minus 1 for the constant B, and a key space of 61 characters, there are roughly 2.65 x 10<sup>21</sup> possible combinations. If I could verify a million URLs a minute, it would take over 5 billion years to verify all combinations — whew.
But I don’t need to verify all combinations. Even if I were able to verify 0.000000001% I would still have 26 billion URLs. 26 billion URLs worth of potentially highly confidential information.
So, I write a Python script to generate alphanumerical codes 12 characters in length, and check if they are valid by firing an HTTP GET request to Mimecast. A response of 200 OK indicates an invalid URL and a 307 Redirect indicates valid. With some tweaking, I was able to consistently check around 600 URLs a second on a single AWS small instance, and on average I was finding 1.3 valid URLs every second. Within 9 hours I had found over 40,000 valid URLs.
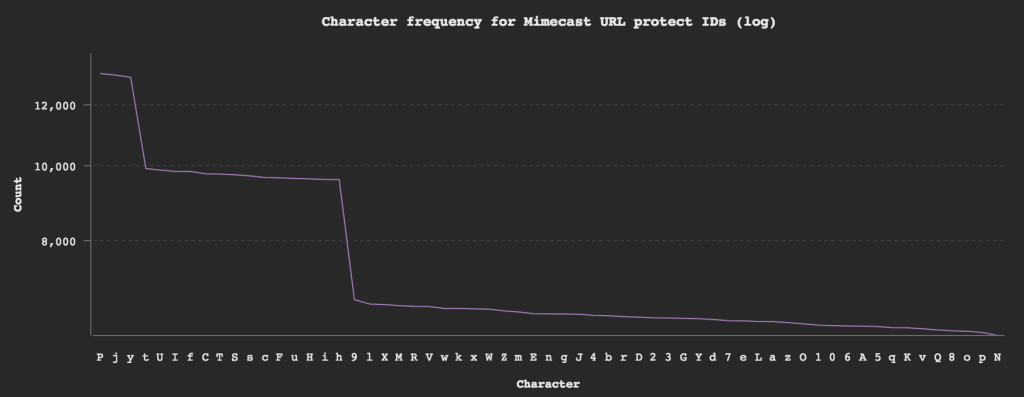
Let’s breakdown the URL ID and see if we can spot any patterns by plotting the character frequencies.
-
Characters
P j yhave over a 2 x chance of appearing. -
t U I f C T S s c F u H i hhave a 1.5 x chance of appearing.
By weighting these characters, I increased the finding rate from 1.3/second to 1.9/second.
I then analysed the frequency of each character in every position. I found that for position 3 and 6, characters P j y actually had a 5 x chance of appearing and at the 8th position these characters had zero chance. For the 11th position characters C c F f H h I i S s T t U u had a 7 x chance of appearing in that position. By weighting the characters at these positions my find rate went up to to 2.6/second.
What about that B? Why is it always the 5th character — a separator perhaps? Maybe the first 4 characters are a “key”. Let’s see if there are any common keys:
P@box:~$ cat ids.txt | cut -c1-4 | sort | uniq -c | sort -nr | head -n10
3 X862
3 iITP
3 EPpH
3 Cj6i
2 Zxj9
2 Zt6a
2 ZSP3
2 ZpOX
2 Zpj0
2 ZLnj
Hmm. Nothing really to draw a conclusion from and the URLs seemingly don’t have any connection. Let’s try the other way around by brute forcing IDs starting with X862B XXXXXXX. With 4 less characters to guess, my find rate went up to almost 4/second.
After I found a couple of hundred valid URLs, I filtered through the results and found about 20% of redirected URLs contained an e-mail address from newsletters and the sort. To my surprise, all of the e-mail addresses were related to the same company that, for the purposes of this article, I will call Charlie’s Construction. Furthermore, about 60% of the URLs were all related to the construction industry. This can’t be a coincidence. The first four characters of an ID must map to a company somehow.
I now have some good insights in to what e-mails Charlie’s Construction receives and I could identify their customers, suppliers and IT provider. I could even see a bunch of links to a restaurant which happens to be around the corner from their office. If I were a malicious actor this is a lot of useful information that would make for great phishing campaigns.
More than just links…
In order to speed up manually checking 40,000 URLs, I wrote another script to take a screenshot of each page so I could very quickly flick through them. Every now and again I was getting a corrupt image file, much larger than the average image. After some investigation I realised they were files — attachments people had sent via e-mail. In fact, about 7% of the 40,000 URLs were files. These files ranged from malware, pictures, invoices, sales documents, marketing plans, internal reports, mortgage applications, property deeds, tax returns, financial performance figures, compliance and regulatory reports, client contracts — oh my!
That’s a lot of confidential information which could have disastrous affects in the wrong hands.
Targeting
Instead of using a shotgun approach, could we use this type of attack to target an organisation? i.e could we find the “key” for Dave’s Defence Services? Sure, we could e-mail the target a link and socially engineer them to reply so we can see the replaced URL. Or we could just ask Mimecast for it…
After scratching my head a while, I stumbled along ”Mimecaster Central” which is their support community. Users can contribute to the community, write articles and provide advice on best practices. Their search functionality allows you to find users by company, which Mimecast happily lists.
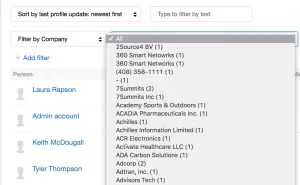
Each user on Mimecaster Central has a profile: https://community.mimecast.com/people/user.XDJJBtax1JX — look familiar? We now have an ID of a user at Dave’s Defence Services. And as expected running a brute force attack against XDJJB XXXXXXappears successful and upon investigation reveals interesting e-mails and files relating to Dave’s Defence Services.
I want to point out that not all IDs starting with XDJJB linked to Dave’s Defence Services, and I found other users working at this organisation whose ID starts with something entirely different. I was unable to figure out Mimecast’s algorithm for generating these IDs.
The fix
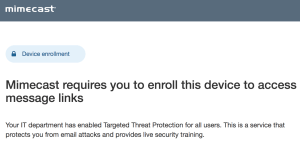
I wouldn’t classify this a bug or a security flaw, per se, but there is definitely more Mimecast can do to prevent these types of attacks from being used in the wild. In fact, Administrators using Mimecast can protect links by requiring users to enrol their device first but I found that it was rarely used.
There are two relatively simple things Mimecast can do to protect against this type of attack:
-
Increase the ID length. Mimecast is not a URL shortener, it doesn’t need short URLs. By increasing it’s length to at least 128 characters — much like it’s competitors — it will make this type of attack infeasible.
-
Rate limit by IP address access to the protect-*.mimecast.com domains — no user is going to click 400 links a second.
Disclosure timeline
Mimecast’s responsible disclosure guidelines were followed and the issue was raised directly with their security team.
-
1st November 2017 — Research conducted
-
3rd November 2017 — Mimecast notified
-
6th November 2017 — Reply from The Mimecast Responsible Disclosure Team recognising the issues and that they are already working on a fix.
-
9th November 2017 — Reply from Mimecast’s CISO, Mark O’Hare with further details.
-
9th November 2017 — Mimecast implement rate limiting globally
-
19th December 2017 – Mimecast changed URL Protect IDs to be exponentially longer, rendering a brute force attack impracticable.
-
13th March 2018 – Mimecast finish “Customer Outreach” regarding issue.
-
15th March 2018 – Schillings publish this article.=