Ahh shhgit!
Finding secrets in open source code in real time.
DevSecOps — the art of embedding security into the software development lifecycle — is a common and largely underestimated threat vector for many organisations. Software developers can accidentally leak sensitive information, particularly secret keys for third party services, across code hosting platforms such as GitHub, GitLab and BitBucket. These secrets — including the data they were protecting — end up in the hands of bad actors which ultimately leads to significant data breaches. Much like we saw with the Capital One data breach in early 2019, the Canadian banking giant Scotiabank screw-up, and the Uber 2016 data breach.
Finding these secrets across GitHub is nothing new. There are already many open-source tools available to help with this depending on which side of the fence you sit. On the adversarial side, popular tools such as gitrob and truggleHog focus on digging in to commit history to find secret tokens from specific repositories, users or organisations. Recent research from North Carolina State University found that many of the secrets accidentally committed to GitHub are cleaned up within 24 hours, rendering said tools rather ineffective in practice.
On the defensive side, Amazon AWS labs have a tool called git-secrets that helps prevent committing secrets in the first place. And GitHub themselves are actively scanning for these secrets with their token scanning project. The project aims to identify secret tokens within recently committed code and notify the secret provider who will contact the owner and in most cases automatically revoke the token to prevent abuse. As of 15 October 2019, GitHub have on-boarded 15 providers including giants like Amazon, Dropbox, Slack and Stripe. Here is an example of Discord’s notification:
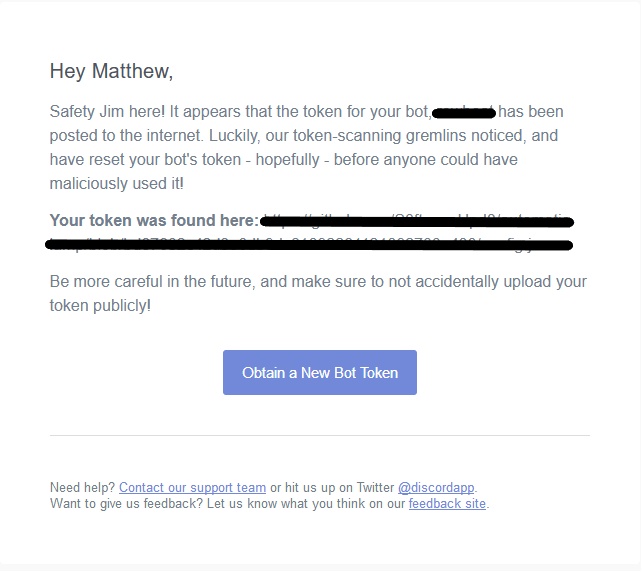
But how robust is this process in practice? What if you could do the same but in an adversarial manner? Imagine being able to monitor the entirety of GitHub, GitLab and BitBucket to find any secrets accidentally committed in real time. Well, we’re in luck. All three platforms provide a public ‘real time firehose’ events API which details various activity streams on the site including all recent code commits.
Introducing shhgit!
Inspired by gitrob, my new tool shhgit will watch these real-time streams and pull out any accidentally committed secrets. It works like this:
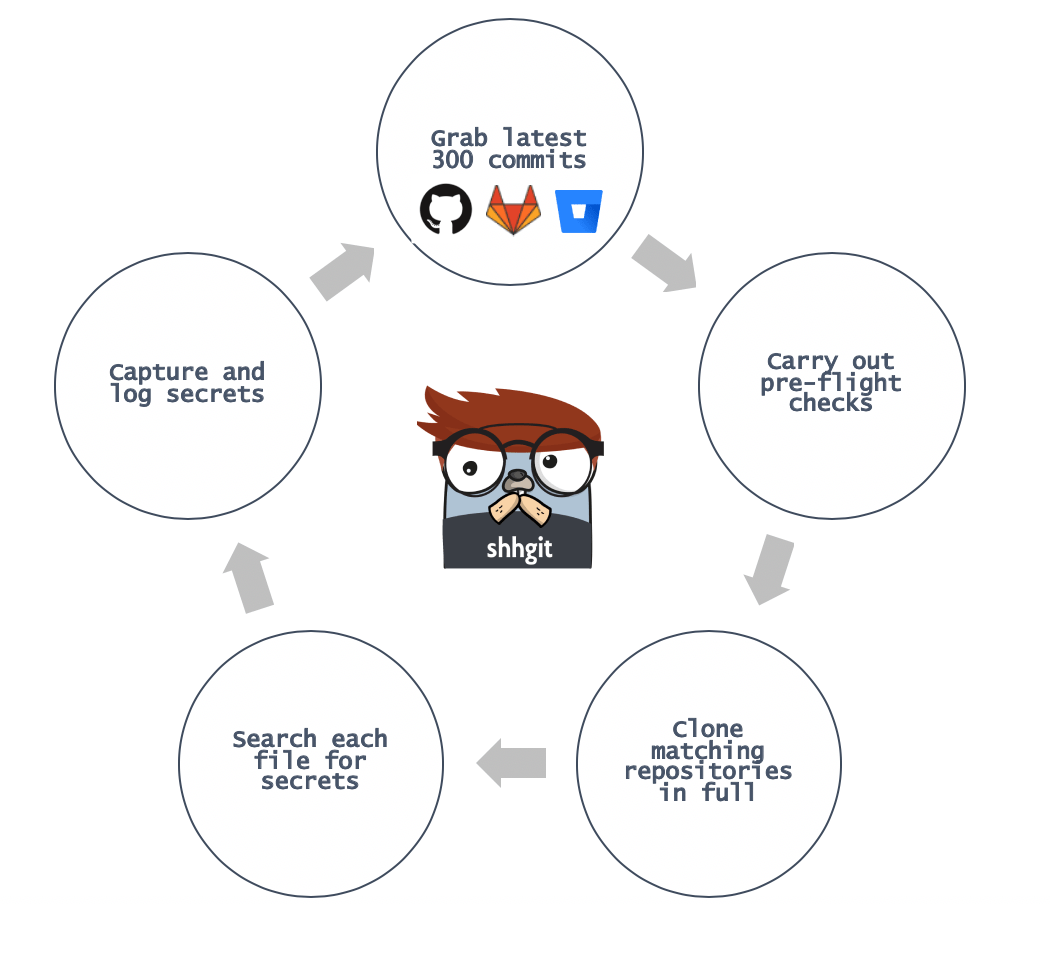
Pre-flight checks can be anything from ensuring the repository is below a particular size, has a certain number of stars, or isn’t a fork. We then match the filename, path, extension, and the files contents against 120 signatures. So how does shhgit fair in practice? Within 48 hours I was able to identify the following secrets:
| Secret Type | Count | Verified | Valid (%) |
|---|---|---|---|
| Username and Password in URI | 1,351 | 440 | 32.5% |
| Amazon AWS | 117 | 58 | 49% |
| Google OAuth keys | 231 | 174 | 75.3% |
| MailGun API keys | 194 | 87 | 44.8% |
| Slack Webhook URLs | 139 | 62 | 44.6% |
| SQLite databases | 33 | - |
I was finding and verifying secrets within ~7 minutes of them being committed. And as you can see from the verified column, around 50% of them were valid meaning I could access the respective service using the captured credentials/keys. This suggests that either GitHub’s token scanning isn’t quick enough or their patterns aren’t matching everything. I suspect it’s a bit of both.
You can access shhgit live here. Watching the screen scroll through secret after secret is quite mesmerising.

Unexpected item in bagging area
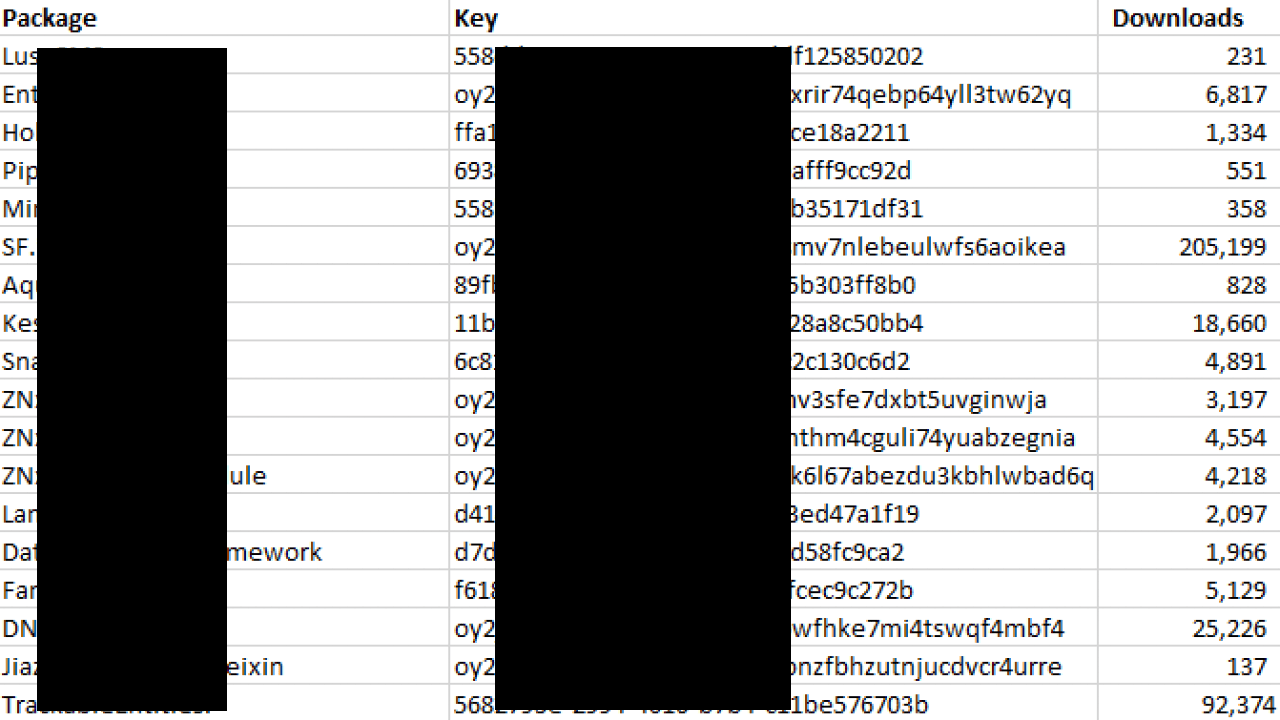
What I didn’t expect to find was valid package manager API keys, i.e., npm for Node.js; PyPi for Python; and NuGet for C#. The total number of downloads for these packages is in the millions. And the majority of these keys had publishing permissions. Meaning a bad actor could theoretically embed malicious code into the packages, reupload them without detection, and potentially infect millions of devices. These are just some redacted keys for NuGet packages:
Na na na na Na na na na GITMAN!
“Username and Password in URI” is by-far the most common found type of secret, i.e.: scheme://username:password@hostname:port. Perhaps unsurprisingly the majority of these are databases, e.g., PostgreSQL, MongoDB, MySQL, etc. And because of the standardised URI format we can easily and automatically verify the credentials for popular schemes:
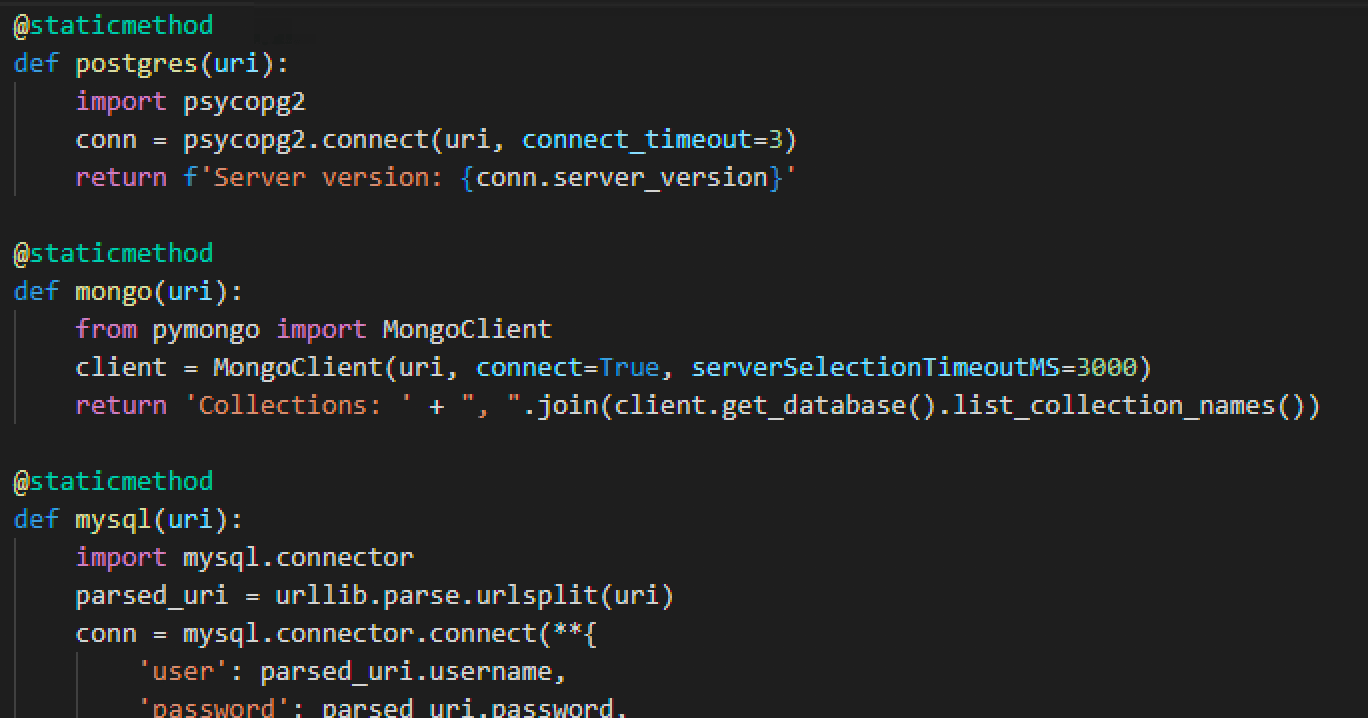
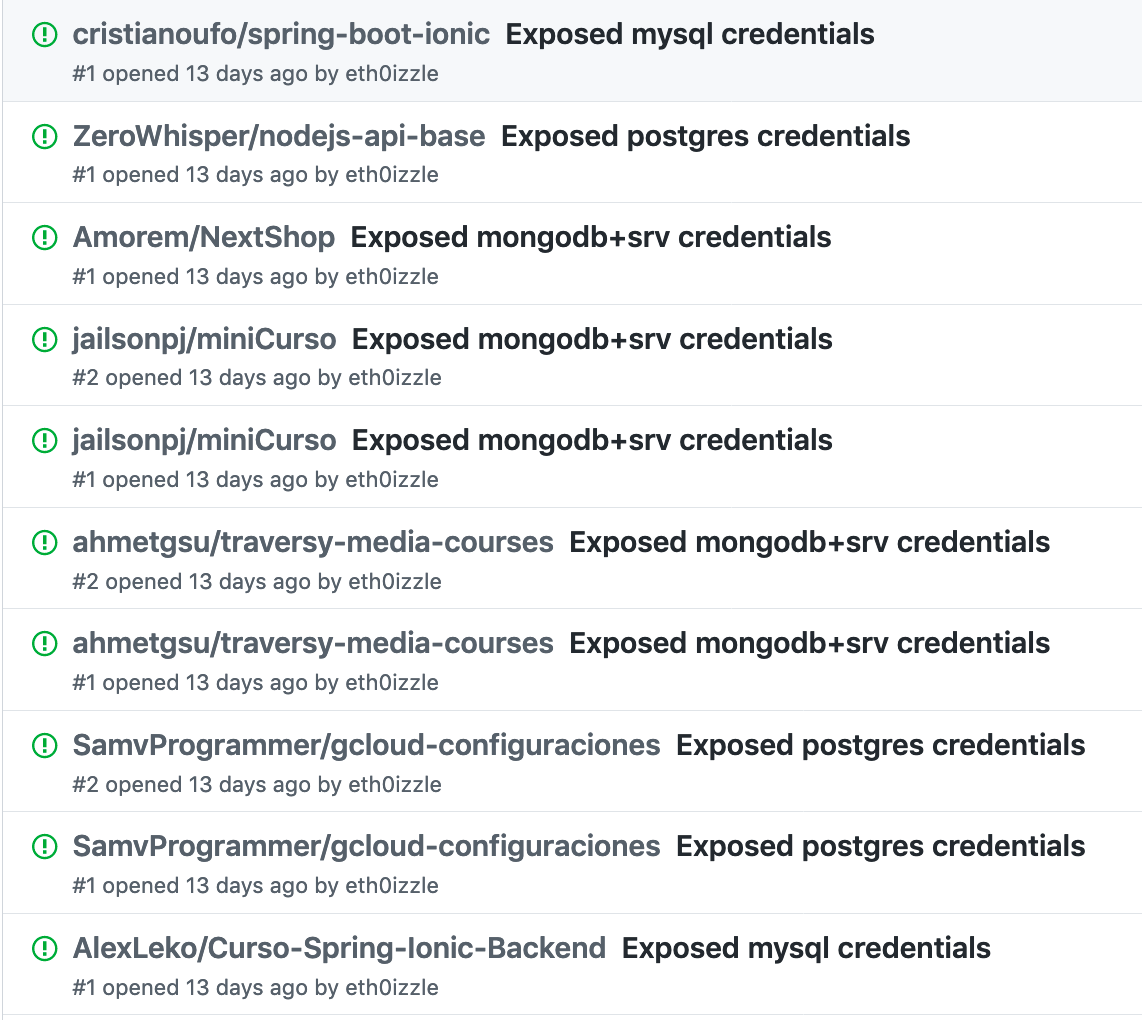
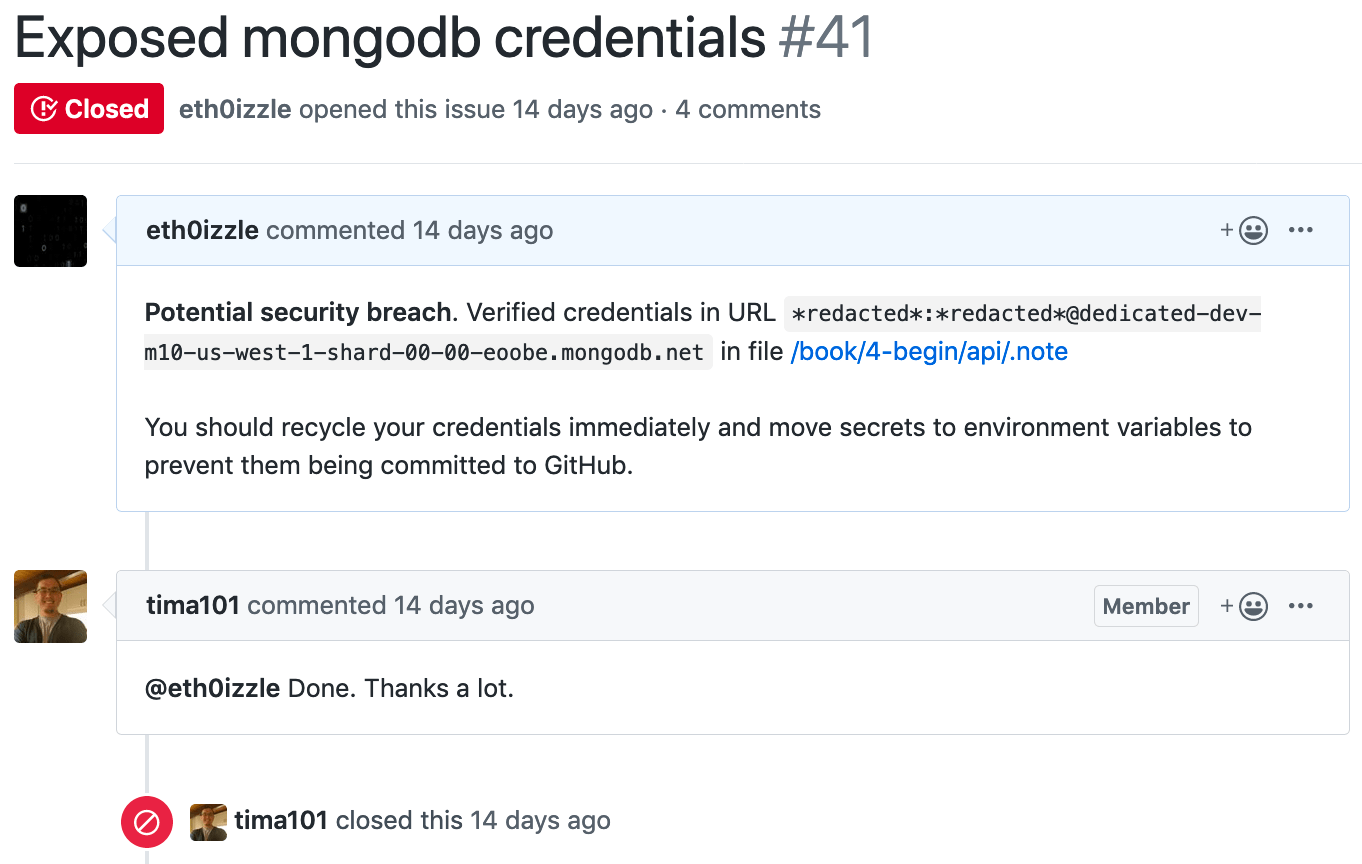
And if the connection is successful — and because we’re a Good Samaritan — we can automatically raise an issue with the code maintainers on the platform the secret was found.
So what?
As I mentioned at the beginning of my post, leaking secrets in to public code repositories is nothing new. The problem has existed since the launch of GitHub and other services over 10 years ago. And from the recent data breaches the implications are clear: reputational damage and huge fines. But we — software developers, team managers, organisations — should be doing more:
- Ensure secrets don’t end up in your code base in the first place. They should be a part of your environment. At a minimum, config files should be encrypted with a environment-based key. The Travis CI docs have a great guide on this.
- Use automated tools such as git-secrets to prevent secrets being committed.
- Provide training - and equally take the initiative to seek out training — on best practices and secure coding standards and guidelines.
- Make sure you are across your vendors who are developing code or apps for you. Ignorance isn’t good enough. Ask the right questions.
And hopefully you won’t be exclaiming ahh shhgit!